5. How Representative Is Your Government?
Is Canada’s parliamentary system of government democratic?
Yes. Next question.
Ok. But how representative is it? Well that’s something worth exploring. First, what do I mean by “representative?” It’s not necessarily intuitive that all governments need to consider the will of their citizens when setting policy. I don’t believe China’s National People’s Congress has any legal obligation to consult with its people or even consider their thoughts. Technically, our government rules in right of sovereign of the United Kingdom and the Commonwealth realms who could, in theory, tell us how they’d like things run.
Through decisions made centuries ago by ancestors and predecessors of Queen Elizabeth II, our system is founded on popular elections. That means our legislators are chosen by us and, for all intents and purposes, govern in our right. So every few years we get to throw the old set of representatives out and choose the next one.
But what about in between elections: where do our members of parliament look for their day-to-day instructions? I believe some simple data analytics can help us answer that question. I’m going to see how often members of parliament vote strictly along party lines. If they’re always following their party leaders, then it would seem it’s the parties who they serve. If, on the other hand, they often cast votes independently of their parties, then they might be thinking more about their own constituents.
This won’t definitively prove anything one way or the other but, if we can access a large enough data set, we should be able to draw some interesting insights.
We’ll begin on a webpage managed by the House of Commons itself: Parliament’s Open Data project - ourcommons.ca/en/open-data. The page explains how we can make use of a freely-available application programming interface (API) to download and manipulate detailed data representing the core operations of Canada’s legislature.
Like many APIs in use these days, the precise syntax you need to get the data you’re after can be a bit of a puzzle. But since most programmers enjoy puzzles, this isn’t a big deal. The OurCommons API expects you to play around with URLs based on the base address, ourcommons.ca/Members/. Adding en tells the server that you want service in English. Adding a forward slash and then the word votes means that you’re looking for voting records.
Some resources are available in XML formatting, while others can be downloaded in the spreadsheet-friendly CSV format. But we’re going to stick with plain old HTML for our purposes. That means any URL you see here can be loaded and enjoyed in your browser just like any other webpage.
We’ll begin with the Votes page - ourcommons.ca/Members/en/votes. The main data on this page consists of a table listing all the bills associated with a particular parliamentary session.
A parliament, in this context, is all the sittings occurring between the formation of a new government after one election, until its dissolution before the next election. A session is a few months' (or even years') worth of sittings. The second session of the 41st Parliament (which stretched from October 16 2013 until August 2, 2015) would be represented by this URL:
https://www.ourcommons.ca/Members/en/votes?parlSession=41-2
That URL would present you with links to all the votes from that session. If you preferred to see only private members' bills from that session, you could add the bill document argument: TypeId=4. Substituting TypeId=3 for that, as with the next example, would return all house government bills. This example points to house government bills from the current session (the second session of the 43rd parliament):
https://www.ourcommons.ca/Members/en/votes?parlSession=43-2&billDocumentTypeId=3
If you’d prefer, you can move between views on the website itself through the various drop-down menus. But to get the sheer volume of data we’re after, we’ll need the power of some well-written Python code.
What’s the difference between members and government bills? The former are sponsored by regular members of parliament of any party, while the latter are always sponsored by cabinet ministers and reflect the government’s official position.
I would expect that parties are more likely to at least try to force the compliance of all their members when it comes to voting on government bills. Private members' bills would, perhaps, be more likely to encounter independent support or opposition. It also seems likely that we’ll find more fractured voting among opposition parties for government bills than for members of the government. Dissension should, by that same token, be equally present within all parties for private members' bills.
Let’s see if the data bears out our assumptions.
Scraping data from a single vote
With those introductions out of the way, let’s start pulling some data. Converting the webpage for a single vote into a Pandas dataframe is surprisingly simple. After importing the Python Pandas library, I only need to pass a URL (for the seventeenth vote of the second session of the 43rd parliament, in this case) to the pd.read_html command. Pandas will read the page’s HTML, identify data relationships, and convert everything to a table.
import pandas as pd
dfs = pd.read_html('https://www.ourcommons.ca/Members/en/votes/43/2/17',header=0)
For some reason, the specific data we’re after exists in the dataframe identified as dfs[0] (rather than just dfs). I can’t say I understand why that is, but it is. So for convenience, I’ll push that to the new dataframe, df:
df = dfs[0]
Let’s see what our data looks like:
df.shape
(319, 4)
There are four columns, comprising 319 rows. That means 319 members cast votes for this bill.
To keep things clean, I’ll change the names of the column headers and then display the first five rows of data:
df.columns = ['Member','Party','Vote','Paired']
df.head()
Member Party Vote Paired
0 Mr. Ziad Aboultaif(Edmonton Manning) Conservative Nay NaN
1 Mr. Scott Aitchison(Parry Sound—Musk) Conservative Nay NaN
2 Mr. Dan Albas(Central Okanagan—Si... Conservative Nay NaN
3 Mr. Omar Alghabra(Mississauga Centre) Liberal Nay NaN
4 Ms. Leona Alleslev(Aurora—Oak Rid... Conservative Nay NaN
All the votes of these first five members went against the bill (“Nay”). An affirmative vote would be identified as “Yea.”
We can easily see how the party numbers broke down using the .value_counts() method:
df['Party'].value_counts().to_frame()
Party
Liberal 146
Conservative 115
Bloc Québécois 31
NDP 22
Green Party 3
Independent 2
I’m sure you’re impatiently waiting to hear how the vote went. Once again, it’s .value_counts() to the rescue:
df['Vote'].value_counts().to_frame()
Vote
Nay 263
Yea 56
Not a happy end, I’m afraid. The bill was shot down in flames.
Automating vote tabulation
That’s how a single vote will look. Lets take what we’ve learned and build a program that will automate the process of scraping and then tabulating hundreds of votes at a time.
The first problem we’ll need to solve is identifying the votes we want to analyse. I’ll use our old friend pd.read_html to scrape the page that lists all the votes on private members' bills from the first session of the 42nd parliament. I’ll then pass the data to a new dataframe called vote_list.
dfs_vote_list = pd.read_html('https://www.ourcommons.ca/Members/en/votes?parlSession=42-1&billDocumentTypeId=4',header=0)
vote_list = dfs_vote_list[0]
Now, since I’m going to have to keep track of the number of voting types as their records are scraped, I’ll initialize some variables and set them to zero. There will be a party line and non party line variable for each party so we’ll know how many of each category we’ve seen. I’ll also track the total number of voting bills we’re covering.
total_votes = 0
partyLineVotesConservative = 0
non_partyLineVotesConservative = 0
partyLineVotesLiberal = 0
non_partyLineVotesLiberal = 0
partyLineVotesNDP = 0
non_partyLineVotesNDP = 0
partyLineVotesBloc = 0
non_partyLineVotesBloc = 0
Once the core program is run, we’ll iterate through four functions - one for each party. The functions will enumerate the Yeas and Nays and then test for the presence of at least one Yea and one Nay to identify split voting. If there was a split, the function will increment the non party line variable by one. Otherwise, the party line variable will be incremented by one.
Here’s one of those functions:
def liberal_votes():
global partyLineVotesLiberal
global non_partyLineVotesLiberal
df_party = df[df['Party'].str.contains('Liberal')]
vote_output_yea = df_party['Vote'].str.contains('Yea')
total_votes_yea = vote_output_yea.sum()
vote_output_nay = df_party['Vote'].str.contains('Nay')
total_votes_nay = vote_output_nay.sum()
if total_votes_yea>0 and total_votes_nay>0:
non_partyLineVotesLiberal += 1
else:
partyLineVotesLiberal += 1
Our next job will be to build a list of the URLs we’ll be scraping. This example reads the private members' bills from the first session of the 42nd parliament. We’re only interesting in collecting the relevant vote numbers from each row so we can add them to the base URL (identified as https://www.ourcommons.ca/Members/en/votes/42/1/ in the code).
The problem is that the vote numbers are listed as No. 1379 and so on. The string fragment No. is going to get in the way. The code vote_list['Number'].str.extract('(\d+)', expand=False) will strip out all non-numeric characters, leaving us with just the numbers themselves.
dfs_vote_list = pd.read_html('https://www.ourcommons.ca/Members/en/votes?parlSession=42-1&billDocumentTypeId=3',header=0)
vote_list = dfs_vote_list[0]
vote_list.columns = ['Number','Type','Subject','Votes','Result','Date']
vote_list['Number'] = vote_list['Number'].str.extract('(\d+)', expand=False)
base_url = "https://www.ourcommons.ca/Members/en/votes/42/1/"
url_data is the name of a new dataframe I create to contain our set of production-ready URLs. I then run a for-loop that will iterate through each number from the Number column and add it to the end of the base URL. Each finished URL will then be appended to the url_data dataframe.
url_data = pd.DataFrame(columns=["Vote"])
Vote = []
for name in vote_list['Number']:
newUrl = base_url + name
Vote.append(newUrl)
url_data["Vote"] = Vote
The first lines of that dataframe will look like this:
url_data.head()
Vote
0 https://www.ourcommons.ca/Members/en/votes/42/...
1 https://www.ourcommons.ca/Members/en/votes/42/...
2 https://www.ourcommons.ca/Members/en/votes/42/...
3 https://www.ourcommons.ca/Members/en/votes/42/...
4 https://www.ourcommons.ca/Members/en/votes/42/...
I’ll want to save those URLs to a permanent file so they’ll be available if I want to run similar queries later. Just be careful not to run this command more than once, as it will add a second (or third) identical set of URLs to the file, doubling (or tripling) the number of requests your program will make.
url_data.to_csv(r'url-text-42-1-privatemembers',
header=None, index=None, sep=' ', mode='a')
This brings us at last to the program’s core. We’ll use another for-loop to iterate through each URL in the file, read and convert the content to a dataframe, rename a couple of column headers to make them easier to work with, and then test for unanimous votes (i.e., bills which generated no Nay votes at all).
Why bother? Because unanimous votes - often motions to honour individuals or institutions - will teach us nothing about normal voting patterns and, on the contrary, could skew our results. If a vote was unanimous, continue will tell Python to skip it and move on to the next URL.
For all other votes (else), the code will call each of the four functions and then increment the total_votes variable by one.
URLS = open("url-text-42-1-privatemembers","r")
for url in URLS:
# Read next HTML page in set:
dfs = pd.read_html(url,header=0)
df = dfs[0]
df.rename(columns={'Member Voted':'Vote'}, inplace=True)
df.rename(columns={'Political Affiliation':'Party'}, inplace=True)
# Ignore unanimous votes:
vote_output_nay = df[df['Vote'].str.contains('Nay', na=False)]
total_votes_nay = vote_output_nay['Vote'].str.contains('Nay', na=False)
filtered_votes = total_votes_nay.sum()
if filtered_votes==0:
continue
# Call functions to tabulate votes:
else:
liberal_votes()
conservative_votes()
ndp_votes()
bloc_votes()
total_votes += 1
That’s all the hard work. I wrapped things up by printing out each of the variables with their final values:
print("We counted", total_votes, "votes in total.")
print("Conservative members voted the party line", partyLineVotesConservative,
"times, and split their vote", non_partyLineVotesConservative, "times.")
…And so on.
What did we learn?
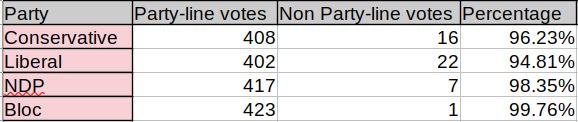
Oh. You’re still here? I guess you’re curious about the results. Well how could I ever disappoint such a loyal and persistent reader? So here’s what came back from scraping all government-sponsored bills from session 42-1:
We counted 424 votes in total.
Conservative members voted the party line 408 times, and split their vote 16 times.
Liberal members voted the party line 402 times, and split their vote 22 times.
NDP members voted the party line 417 times, and split their vote 7 times.
Bloc members voted the party line 423 times, and split their vote 1 times.
Out of 424 non-unanimous votes (there were 439 votes in total), Conservative members dissented from their party line 16 times, NDP members seven times, and the Bloc only once. But here’s the interesting bit: Liberals - who, as I’m sure you know, were the government for this session - dissented more than any other group: 22 times. That’s more than 5%. So much for my assumption about governing parties and party discipline. Or perhaps that’s a product of the quality of their legislative program.
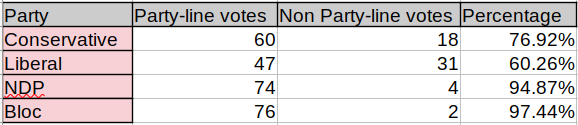
The results did, however, confirm a separate assumption: split votes are, indeed, more common for private members' bills. Here’s how those numbers looked:
I did wonder whether my 0-vote threshold for split votes was too strict. Perhaps having just one or two rogue members in a party vote isn’t an indication of widespread independence. Would it be more accurate to set the cut off at a higher number, say 3? I can easily test this. All that’s necessary is to change this line in each of the four party functions:
if total_votes_yea>0 and total_votes_nay>0:
To this:
if total_votes_yea>2 and total_votes_nay>2:
…And run the code again. When I did that, here’s what came back:
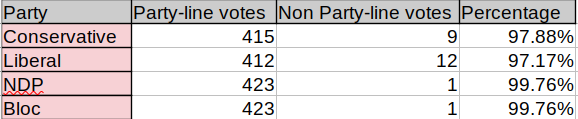
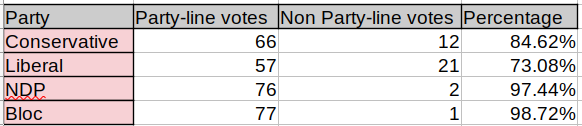
That’s noticeably different, suggesting that there isn’t significant voting dissension among the ranks of our political parties.
Could government be more representative?
When everything’s said and done, our data showed that members for the most part voted with their parties at least 95% of the time. Given how they seem to vote, do we really need all those hundreds of MPs? Wouldn’t it be enough to simply vote for a party and let whichever party wins select cabinet ministers from among all Canadian citizens?
Of course, MPs do much more than just vote. They work on parliamentary committees and attend to the needs of their constituents through local constituency offices.
But why couldn’t parties appoint their own people to staff those committees? And why couldn’t qualified individuals without official links to a political party be hired to staff constituency offices?
Ok. Now how about the fact that, behind the scenes, party caucuses provide important background and tone that helps party leaders formulate coherent and responsive policies? Yeah. Sure they do.
I’m not saying that MPs aren’t, by and large, hard-working and serious public servants. And I don’t think they’re particularly overpaid. But I’m not sure how much grass roots-level representation they actually provide.